- Home
- »
- Next Generation Technologies
- »
-
Synthetic Data Generation Market Size Report, 2024-2030GVR Report cover
![Synthetic Data Generation Market (2024 - 2030)Report]()
Synthetic Data Generation Market (2024 - 2030)
Size, Share & Trends Analysis Report By Data (Tabular Data, Text Data, Image & Video Data, Others), By Modeling, By Offering, By Application, By End Use, By Region, And Segment Forecasts
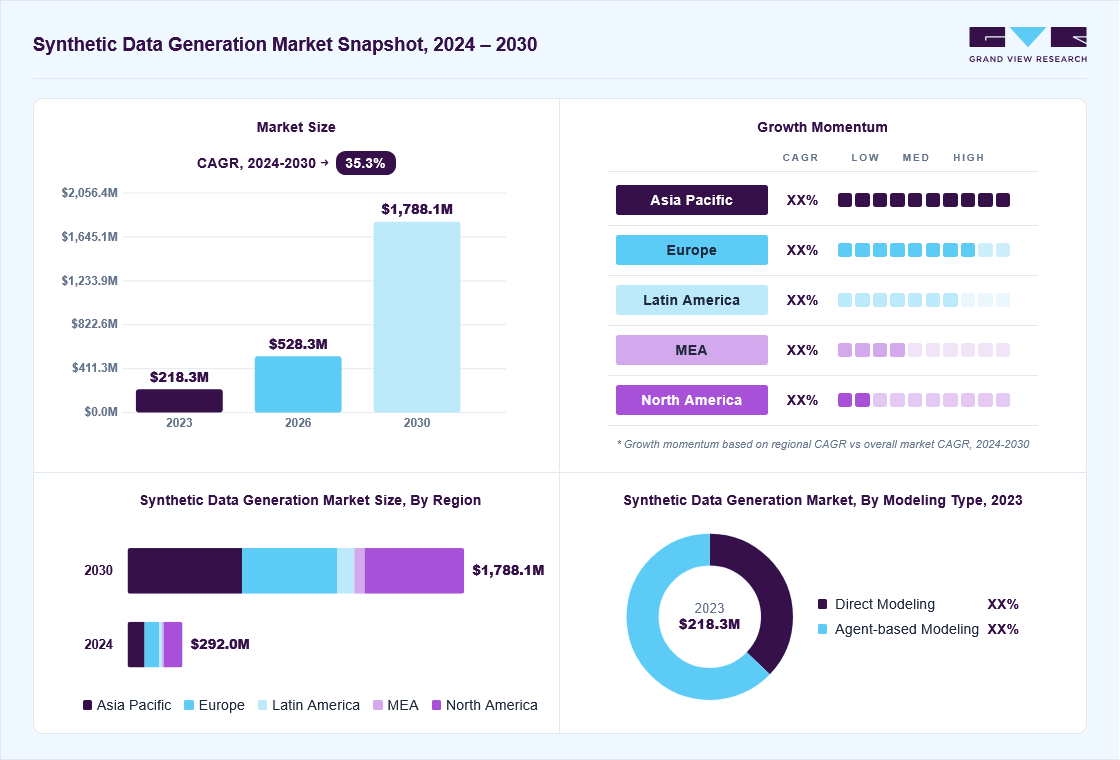
Market Size, 2023
$218.3MMarket Estimate, 2026
$528.3MMarket Forecast, 2030
$1,788.1MCAGR, 2024–2030
35.3%Synthetic Data Generation Market Summary
The global synthetic data generation market size was valued at USD 218.3 million in 2023 and is projected to grow from USD 528.3 million in 2026 to USD 1,788.1 million by 2030, at a CAGR of 35.3% from 2024 to 2030. The market in North America dominated with a revenue share of 34.5% in 2023. The emergence and increasing application of technologies such as Artificial Intelligence (AI), Machine Learning (ML), and the Internet of Things (IoT), an increasing use of connected device technology, is primarily driving the growth of this market.
Key Market Trends & Insights
- North America dominated the global synthetic data generation market, accounting for 34.5% in 2023.
- The U.S. synthetic data generation market held the regional industry's largest revenue share in 2023.
- Based on data, the tabular data segment dominated the global industry for synthetic data generation and accounted for a revenue share of 38.8% in 2023.
- Based on modelling, the direct modeling segment is expected to experience significant CAGR during the forecast period.
- Based on offering, the fully synthetic data segment is expected to dominate the global market for synthetic data generation in 2023.
Market Size & Forecast
- 2023 Market Size: USD 218.4 Million
- 2030 Projected Market Size: USD 1,788.1 Million
- CAGR (2024-2030): 35.3%
- North America: Largest market in 2023
- Asia Pacific: Fastest growing market
In addition, the rising dependence on business processes such as effective marketing and customer engagement on data availability, especially in industries such as entertainment and media, retail, and others, is developing an upsurge in demand for data generation. Synthetic data is extensively used in modern technology applications such as training AI/ML models and vision algorithms, developing predictive analysis solutions, and more. Multiple customer-oriented industries such as healthcare, finance, real estate, and others, where customer data and its privacy are highly regulated, utilize synthetic data for various functions, including research, dynamic content development for marketing, and effective content delivery.The rapid pace of digital transformation, the inclusion of technologies such as IoT, and the growing adoption of automation under "Industry 4.0" have enormous influence on multiple industries, including manufacturing. However, increasing data privacy and security concerns, stringent regulations regarding the use of customer data, and the scarcity of reliable data present barriers to the seamless integration of technology for processes such as quality control.
")
Multiple manufacturing industry participants rely on synthetic data to address data availability concerns, train machine-learning models, and implement effective technology solutions to produce desired results. Multiple automotive businesses use synthetic data for quality control processes such as simulation and virtual testing, anomaly detection and fault diagnosis, sensor testing, and more. It directly assists the manufacturers in lowering development costs, enhancing product safety, and substantially reducing time to market. For instance, in August 2023, Tech Mahindra Limited, one of the prominent companies in the automotive industry, collaborated with Anyverse SL, a synthetic data generation platform, to accelerate the improvement of computer vision-powered solutions for autonomous applications.
Regulations and laws such as the General Data Protection Regulation (GDPR), the American Privacy Rights Act of 2024, and others present limitations on using real data generated through customer transactions and engagements. However, companies rely on synthetic data to ensure technology integration in developing effective solutions driven by AI or IoT. For example, financial organizations utilize synthetic data to simulate numerous borrower profiles and economic scenarios to test the strength of risk assessment models.
Utilization of real data sets compromises data privacy. Such datasets cannot be shared with third-party participants in business activities. It poses challenges in testing novel technology-driven software, especially in banking and financial services and sharing real data with vendors or service providers to test the technology-based solutions' usability, capability, and suitability. Synthetic data is expected to play a vital role in this area as it protects data privacy while solving the problem of data scarcity.
Data Insights
The tabular data segment dominated the global industry for synthetic data generation and accounted for a revenue share of 38.8% in 2023. Aspects such as the structured nature of tabular data, widespread applicability in numerous sectors, statistical fidelity, and ease of use drive the growth of this segment. Versatility, privacy preservation capabilities, and cost-effective features offered by synthetic data have increased demand. Easy scalability, statistical similarity, and suitability in training AI/ML models fuel this segment's growth. Industries such as healthcare, e-commerce, software development & testing, manufacturing, and others are expected to incorporate tabular synthetic data at a rapid pace.
The image & video data segment is expected to experience the fastest CAGR during the forecast period. The growing need for self-driving cars, autonomous vehicles, and other smart technology products in the automotive industry, which rely on AI, IoT, and machine learning, is driving the demand for synthetic data. This data is essential for testing and quality control before launching these technologies. Automotive companies require synthetic data to develop virtual environments that mimic real-world driving conditions. It helps companies train models regarding diverse driving conditions, including weather, traffic, and more. The growing partnerships among synthetic data generators, technology industry participants, and automotive companies are also contributing to the growth of this segment. For instance, in April 2024, Anyverse, one of the prominent suppliers of synthetic data, collaborated with Sony Semiconductor Solutions Corporation to integrate Anyverse's synthetic data platform and Sony's Image Sensor Models.
Modelling Insights
Agent-based modeling held the largest revenue share of the global synthetic data generation market in 2023. The key growth factor for this segment is the increasing application of the financial industry. Financial organizations require vast data to understand the resilience of risk assessment and fraud detection technologies. However, data privacy regulation and limitations associated with data utility pose challenges in this process. Even with Generative AI and other modern technologies, organizations experience risks related to data privacy concerns, compliance adherence, data quality, and more. To address this problem, companies rely on agent-based synthetic data generation. This type of modeling offers greater data control and transparency. Synthetic data generated through the agent-based modeling allows for demonstration of its risk-free and controlled environment.
Direct modeling synthetic data generation is expected to experience significant CAGR during the forecast period. Direct modeling utilizes Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and other advanced algorithms to simulate the data distributions. It is widely used in healthcare, finance, automotive, computer vision, and data augmentation.
Offering Insights
The fully synthetic data segment is expected to dominate the global market for synthetic data generation in 2023. Fully synthetic data offerings are developed entirely with the help of algorithms without input of any original data. Identifiable and sensitive information or data from the real world is not included in these data sets. The absence of real data identifiers makes it a preferred choice for numerous industries where data privacy and security regulations are extremely stringent. Primary industries utilizing fully synthetic data extensively include healthcare, finance, automotive, and others. Cost efficiency, quick generation, and versatility features offered by fully synthetic data are expected to drive demand for this market in the next few years.
The hybrid synthetic data segment is projected to grow at the fastest from 2024 to 2030. The growth of this segment is mainly influenced by scalability, high quality, and cost-effectiveness. The combination of real data and synthetic values, while protecting the sensitivity of actual data points, ensures improved security, enhanced utility, and more. This offering has wide applications in finance, autonomous systems, Natural Language Processing (NLP), healthcare, machine learning, and others.
Application Insights
Based on application, Natural Language Processing (NLP) segment held the largest revenue share of the global market in 2023. Synthetic data generation is extensively used for generating texts, which mimics human language, augmenting existing data sets, masking sensitive data, and more. Synthetic data generation assists Natural Language Processing (NLP) with domain-specific knowledge and rules. Some of the commonly used techniques for synthetic data generation related to NLP include Template-based generation, Generative Adversarial Networks (GANs), and others.
")
The predictive analytics segment is anticipated to grow at the fastest CAGR during the forecast period. Factors such as the rising use of synthetic data by the financial industry and automotive manufacturers mainly drive the growth of this segment. Companies extensively rely on data to determine strategies, finalize product designs, develop and deliver offerings, and distribute products. However, companies cannot utilize actual data sets to analyze the suitability, flexibility, and resilience of multiple product features, including designs, scalability, and functionality. Synthetic data provides vital opportunities for businesses to incorporate predictive analytics to ensure product enhancements, reduced time to market, and alignment of business strategies with customer preferences.
End Use Insights
The healthcare & life sciences segment dominated the global synthetic data generation market in 2030. The healthcare & life sciences sector has adopted advanced technology solutions largely supported by AI, IoT, or machine learning. Training such technologies with the help of enormous data sets is vital for the healthcare industry to ensure a smooth flow of operations once it reaches complete automation-based operational workflows. However, the use of patient data is extremely regulated in most countries, making it challenging for drug developers, healthcare service providers, and related organizations keen to adopt modern technologies. Synthetic data presents seamless simulation, testing, and research support, which is expected to fuel the growth of this segment. Using synthetic data to improve patient outcomes is projected to increase demand for this market.
The consumer electronics segment is expected to experience the fastest CAGR from 2024 to 2030. This is primarily attributed to the increasing use of synthetic data by this consumer electronics and retail industry to train AL/ML models regarding consumer behavior, preferences, purchase patterns, payment practices, and more. Companies are focusing on attaining this to ensure the development of effective marketing strategies, targeted content delivery, and enhanced customer engagement.
Regional Insights
North America dominated the global synthetic data generation market, accounting for 34.5% in 2023. This is attributed to increasing adoption, rising applications, the availability of effective synthetic data generation solutions, and stringent regulations regarding data privacy and data utility. The presence of multiple large enterprises from the financial sector, automotive manufacturing industry, and retail businesses in the region that are currently focusing on training their AI/ML models to deliver effective outcomes is expected to fuel the growth of this market.

U.S. Synthetic Data Generation Market Trends
The U.S. synthetic data generation market held the regional industry's largest revenue share in 2023. This market is mainly driven by factors such as the increasing focus of multiple healthcare, financial services, and automotive companies on AI-driven solutions, enhancement of machine learning capabilities, rising dependency on data for ensuring an improved product or service delivery, strict laws regarding the use of customer data and growing demand for synthetic data to train AI/ML models.
Europe Synthetic Data Generation Market Trends
Europe is identified as a significant region for the global synthetic data generation market in 2023. The growing availability of synthetic data generation services, rising need from industries such as automotive for simulation, fault and anomaly detection, finance for testing newly developed models and methods related to risk assessments, and increasing inclusion of technologies such as AI, machine learning, and others are some of the key growth driving factors for this market
Germany synthetic data generation market held the significant revenue share of regional industry. Large enterprises primarily influence this market in the automotive manufacturing industry, relying on synthetic data for simulation, safety testing, and training AI models regarding various driving scenarios, including weather, light fluctuations, terrain, and more.
Asia Pacific Synthetic Data Generation Market Trends
Asia Pacific synthetic data generation market is anticipated to experience the fastest CAGR from 2024 to 2030. Rising digital transformation activities in the region, growing reliance on technologies such as AI and ML, increasing demand for autonomous vehicles leading to rising use of synthetic data in the automotive manufacturing industry, and stringent regulations and compliance requirements related to data privacy are driving demand for this market. In addition, the increasing inclusion of synthetic data in sectors such as retail and financial services is expected to increase demand for this market.
The China synthetic data generation market is anticipated to grow at a noteworthy rate during the forecast period. This is attributed to factors such as the growing use of synthetic data in predictive analytics, rising automation across industries, including manufacturing and automotive, ease of availability, and businesses' increasing reliability in data-driven strategic decision-making.
Key Synthetic Data Generation Companies Insights
Some of the key companies involved in the synthetic data generation market include Hazy Limited, kymeralabs, YData, MDClone, Informatica Inc. and others. To address the growing competitive driven by the rapid adoption of synthetic data, the key market participants are adopting strategies such as collaborations, enhanced portfolios, service expansion, innovation and more.
-
Hazy Limited, one of the major market participants in synthetic data generation, offers an end-to-end synthetic data platform that provides multi-table capabilities, more than 50 data types, differential privacy, model comparison, automatic analysis, time series, and more.
-
MDClone, a key organization in synthetic data services, primarily provides expertise to the healthcare and life sciences industry. Its ADAMS Healthcare Data Platform assists healthcare businesses in reducing waste, unlocking data, and creating competitive advantage through advanced technology-driven solutions.
Key Synthetic Data Generation Companies:
The following are the leading companies in the synthetic data generation market. These companies collectively hold the largest market share and dictate industry trends.
- MOSTLY AI
- Synthesis AI
- Statice
- YData
- Ekobit d.o.o. (Span)
- Hazy Limited
- SAEC / Kinetic Vision, Inc.
- kymeralabs
- MDClone
- Neuromation
- Twenty Million Neurons GmbH (Qualcomm Technologies, Inc.)
- Anyverse SL
- Informatica Inc.
Recent Developments
-
In March 2024, Hazy Limited and Unbanx LLC joined forces to introduce an ethical data cooperative comprised of synthetically generated financial transaction data. This marked a step forward for the company in ethical data monetization.
-
In March 2023, Hazy Limited, a key player in the synthetic data generation market, raised USD 9 million in Series A funding. This solidified its position as the synthetic data provider and enabled it to explore the potential of generative AI.
Synthetic data generation market Report Scope
Report Attribute
Details
Market size in 2023
USD 218.3 million
Estimated market size in 2026
USD 528.3 million
Projected market size by 2030
USD 1,788.1 million
Growth rate
CAGR of 35.3% from 2024 to 2030
Base year for estimation
2023
Historical data
2018 - 2022
Forecast period
2024 - 2030
Quantitative units
Revenue in USD million and CAGR from 2024 to 2030
Report Coverage
Revenue forecast, company ranking, competitive landscape, growth factors, and trends
Segments Covered
Data, modelling, offering, application, end use, and region
Regional scope
North America, Europe, Asia Pacific, Latin America, MEA
Country scope
U.S., Canada, Mexico, UK, Germany, France, Japan,China, India, Australia, South Korea, Brazil, South Africa, Saudi Arabia, UAE
Key companies profiled
MOSTLY AI; Synthesis AI; Statice; YData; Ekobit d.o.o. (Span); Hazy Limited; SAEC / Kinetic Vision, Inc.; kymeralabs; MDClone; Neuromation; Twenty Million Neurons GmbH (Qualcomm Technologies, Inc.); Anyverse SL; Informatica Inc.
Customization scope
Free report customization (equivalent up to 8 analysts working days) with purchase. Addition or alteration to country, regional & segment scope.
Pricing and purchase options
Avail customized purchase options to meet your exact research needs. Explore purchase options
Global Synthetic Data Generation Market Report Segmentation
This report forecasts revenue growth at the global, regional, and country levels and provides an analysis of the latest industry trends in each of the sub-segments from 2018 to 2030. For this study, Grand View Research has segmented the global synthetic data generation market report based on data, modelling, offering, application, end use, and region:
-
Data Outlook (Revenue, USD Million, 2018 - 2030)
-
Tabular Data
-
Text Data
-
Image & Video Data
-
Others
-
-
Modelling Outlook (Revenue, USD Million, 2018 - 2030)
-
Direct Modeling
-
Agent-based Modeling
-
-
Offering Band Outlook (Revenue, USD Million, 2018 - 2030)
-
Fully Synthetic Data
-
Partially Synthetic Data
-
Hybrid Synthetic Data
-
-
Application Outlook (Revenue, USD Million, 2018 - 2030)
-
Data Protection
-
Data Sharing
-
Predictive Analytics
-
Natural Language Processing
-
Computer Vision Algorithms
-
Others
-
-
End Use Outlook (Revenue, USD Million, 2018 - 2030)
-
BFSI
-
Healthcare & Life Sciences
-
Transportation & Logistics
-
IT & Telecommunication
-
Retail and E-commerce
-
Manufacturing
-
Consumer Electronics
-
Others
-
-
Regional Outlook (Revenue, USD Million, 2018 - 2030)
-
North America
-
U.S.
-
Canada
-
Mexico
-
-
Europe
-
UK
-
Germany
-
France
-
-
Asia Pacific
-
Japan
-
China
-
India
-
Australia
-
South Korea
-
-
Latin America
-
Brazil
-
-
Middle East & Africa
-
UAE
-
Saudi Arabia
-
South Africa
-
-
Frequently Asked Questions About This Report
The global synthetic data generation market size was valued at USD 218.3 million in 2023 and is estimated at USD 528.3 million for 2026.
The global synthetic data generation market is expected to grow at a CAGR of 35.3% from 2024 to 2030, reaching USD 1,788.1 million by 2030.
North America dominated with a 34.5% revenue share in 2023.
Key players include MOSTLY AI; Synthesis AI; Statice; YData; Ekobit d.o.o. (Span); Hazy Limited; SAEC / Kinetic Vision, Inc.; kymeralabs; MDClone; Neuromation; Twenty Million Neurons GmbH (Qualcomm Technologies, Inc.); Anyverse SL; and Informatica Inc.
Key factors include the emergence and increasing application of technologies such as Artificial Intelligence (AI), Machine Learning (ML), and the Internet of Things (IoT), as well as the increasing use of connected device technology.
About the Author(s)
Next Generation Technologies Research Team
Technology · Next Generation TechnologiesThis report was authored by the next generation technologies research team at Grand View Research - comprising two research analysts, one senior research analyst, and one industry expert - with specialized expertise in the next generation technologies segment of the technology industry. All findings are based on proprietary technology databases, executive interviews, and regulatory analysis, subject to internal peer review prior to publication.
Last Updated:
Speak to Analyst


Need a Tailored Report?
Customize this report to your needs — add regions, segments, or data points, with 20% free customization.
Or view our licence options:

ISO 9001:2015 & 27001:2022 Certified
We are GDPR and CCPA compliant! Your transaction & personal information is safe and secure. For more details, please read our privacy policy.